


Why Kafka Capacity Planning is so Challenging


We’ve all been there. You’re an SRE or a platform engineer, and a new project is about to go live. The product team gives you their best estimates: "We're thinking 50 MB/s on average, with peaks of 100 MB/s during launch."
As the person responsible for the Kafka cluster, a familiar sense of dread creeps in. You know that turning that business forecast into a stable, cost-effective cluster is more art than science. You’ve done the work. You’ve spent days benchmarking instance types, running performance tests, and you have a solid grasp of the throughput r6in.large can handle versus an m5.xlarge.
But the uncertainty lingers. To get capacity "right," you have to juggle a dozen variables:
The topic's retention period.
The log compaction strategy (or lack thereof).
The average size of the messages.
The real number of messages the system will actually see.
The replication factor for durability.
Even with all that data, you know the truth: many of the application teams using your platform can't accurately predict their own traffic patterns. A surprise marketing campaign or a viral feature can shatter your carefully laid plans. So, what do you do? You play it safe. You take your calculated needs and add a generous buffer. You over-provision. It’s the only rational choice to avoid a production outage when a traffic spike inevitably hits.
This is the core dilemma of Kafka capacity management. It's a constant, high-stakes guessing game where you're caught between two bad options:
Over-provisioning: You build a cluster for the worst-case scenario, paying for expensive compute and storage resources that sit idle 95% of the time. Your CFO isn't happy, but at least you can sleep at night.
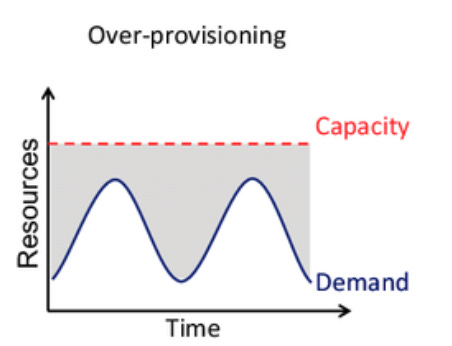
Under-provisioning: You try to run a lean cluster to save costs. It works beautifully until it doesn't. A sudden surge in traffic maxes out your brokers, producers start getting throttled, and the entire data backbone of your company grinds to a halt.
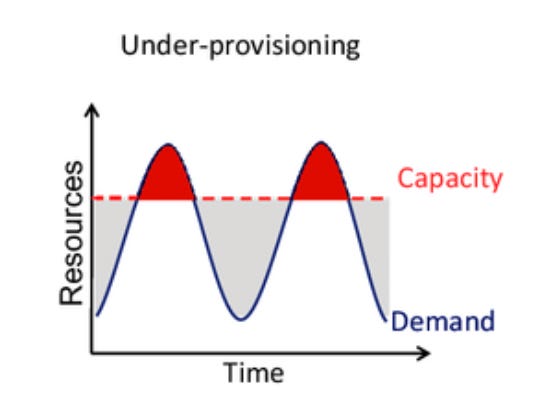
The difficulty boils down to a few hard truths. Benchmarking instances is tedious. Gathering precise requirements from every team is a coordination nightmare. And business traffic, by its very nature, is unpredictable. We're forced to make a high-risk decision based on incomplete information.
The Guessing Game at Hyper-Scale: The POIZON Story

This isn't just a problem for small teams. It's a daily reality for companies running Kafka at the highest levels of scale. Take POIZON, for example. If you're not familiar with them, POIZON is a massive social commerce platform and cultural tastemaker for Gen Z, with over 350 million app downloads and a unicorn valuation backed by firms like Sequoia.
At the heart of POIZON's operations is a massive observability platform built on Apache Kafka. It ingests a torrent of logs, metrics, and traces from their sprawling microservices architecture. For their SRE team, the capacity planning nightmare wasn't just a theoretical problem—it was an operational crisis amplified to an extreme degree.
They faced two compounding challenges:
Hyper-Growth: POIZON's user base and traffic were growing at an explosive rate. This meant the SRE team was in a constant cycle of forecasting future growth, re-evaluating cluster capacity, and planning the next big, painful migration. They were drowning in the operational toil of simply keeping the lights on.
E-commerce Unpredictability: An online marketplace is inherently spiky. A flash sale, a collaboration with a major influencer, or the drop of a highly anticipated sneaker could send traffic skyrocketing with little warning. Their carefully calculated capacity could become obsolete overnight.
This operational treadmill was unsustainable. The constant firefighting and high-stakes capacity planning were burning out the team. They knew they needed a fundamentally different approach, one that could break them out of this painful cycle. This is how they came to AutoMQ.
By migrating their Kafka workload to AutoMQ, POIZON fundamentally changed the rules of the game. The unpredictable traffic spikes were no longer a crisis; they were simply absorbed by AutoMQ's rapid elasticity. The SRE team was no longer forced to over-provision resources "just in case." They could finally run a lean, cost-effective system that automatically scaled to meet real-time demand. The constant cycle of re-evaluation and manual expansion was broken.
So, how was this possible? What was the key that unlocked this new reality for them?
It all comes down to solving a foundational architectural constraint in traditional Kafka: the tight coupling of compute and storage.
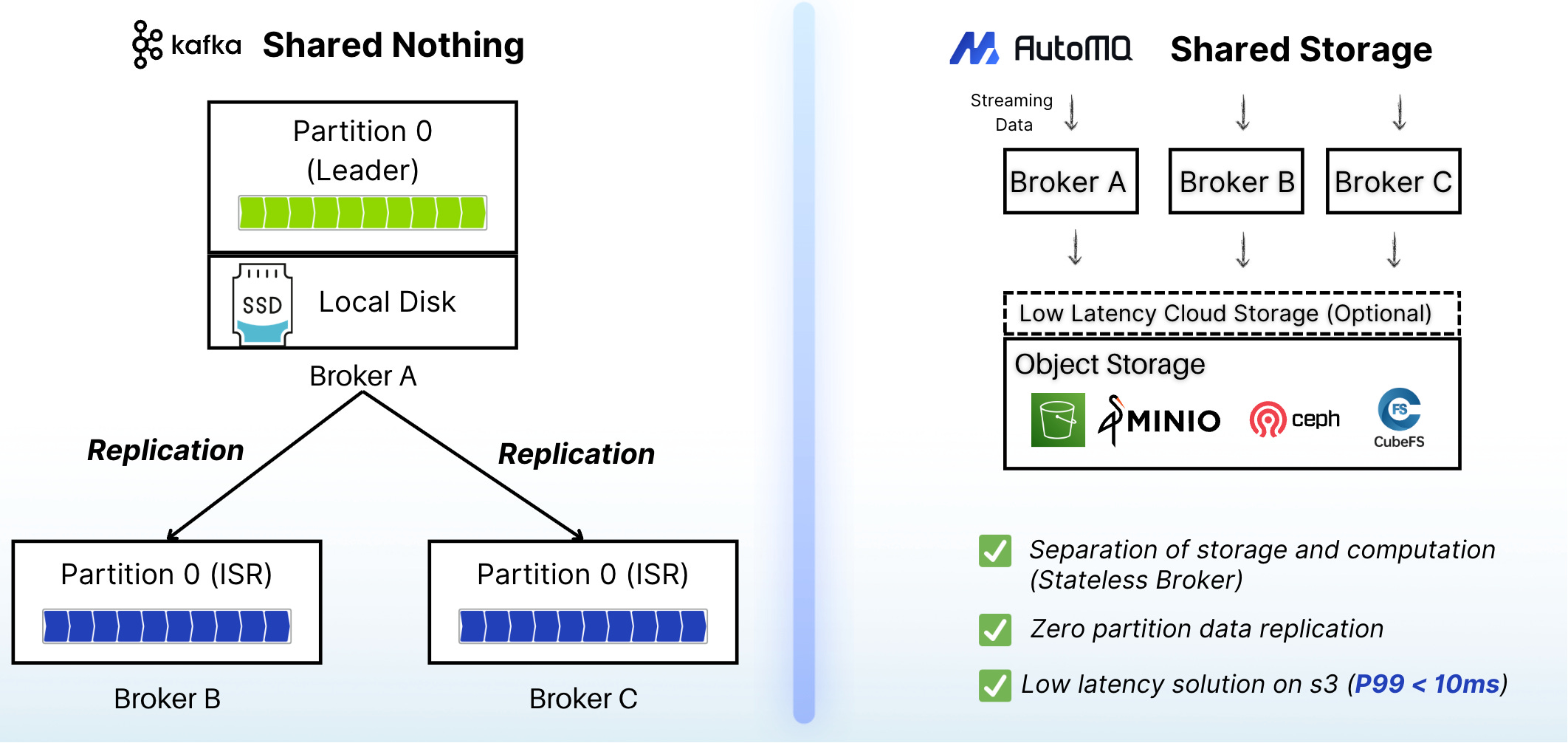
In a standard Kafka deployment, each broker is a stateful node. It's responsible for both processing requests (compute) and storing topic partition data on its local disks (storage). This simple, elegant design was brilliant for its time, but it has a critical side effect in the cloud era: scaling is slow, risky, and expensive.
Adding a new broker means triggering a massive data rebalancing process that can take hours or even days, stressing the existing cluster and putting its stability at risk. This is why you can't just "add a few more nodes" during a traffic spike. You have to plan it weeks in advance. This architectural reality is what forced POIZON—and so many of us—into the capacity guessing game in the first place. And it’s the exact problem AutoMQ was built to solve.
A New Approach: Stop Predicting, Start Reacting
What if the problem wasn't our inability to predict the future? What if the problem was the system's inability to react to the present?
This question is the driving force behind AutoMQ, an open-source, cloud-native Kafka solution we've been building. The core idea is simple but profound: solve the scaling problem by breaking Kafka's fundamental coupling of compute and storage.
AutoMQ re-imagines Kafka's architecture for the cloud. It offloads the durable log storage to cloud object storage—like Amazon S3—while the brokers themselves become largely stateless compute nodes.
This single change completely rewrites the rules of the game.
Because partition data no longer lives on the broker's local disk, moving a partition from one broker to another is no longer a massive data-copying operation. It’s a metadata pointer update that completes in seconds. This enables two transformative capabilities:
Lightning-Fast Elasticity: Need to scale out for a flash sale? You can add new, stateless brokers and they can start serving traffic almost instantly. The cluster can elastically expand and contract to perfectly match the real-time workload, without the hours-long rebalancing delays.
Self-Balancing Clusters: With partition migration being virtually free, the cluster can intelligently and continuously move partitions around to eliminate hotspots and ensure an even distribution of load. No manual intervention required.
Suddenly, the high-stakes capacity guessing game becomes irrelevant.
If your traffic forecast is off by 50%, it doesn't matter. The system adapts. If a "black horse" seller on POIZON's platform drives 10x the expected traffic, the cluster simply scales out to handle it and scales back in when the surge is over.
The risk of under-provisioning vanishes, and the waste of over-provisioning is eliminated. You move from a world of high-risk planning to a world of low-risk automation. Your SRE team is freed from the endless cycle of resizing clusters and can focus on what matters: building reliable products.
This isn't just a concept; it's an open-source project you can explore today. We believe that by re-architecting Kafka for the cloud, we can keep the API developers love while shedding the operational burdens we've all come to accept as "just the way it is."
Stop playing the guessing game. Check out AutoMQ on GitHub and see how a cloud-native architecture can change the rules. Experience open-source AutoMQ locally now with a single command. Looking forward to your feedback
curl -O https://raw.githubusercontent.com/AutoMQ/automq/refs/tags/1.5.1/docker/docker-compose.yaml && docker compose -f docker-compose.yaml up -d